One of the most important abstractions to handle virtual networking in OpenStack clouds are definitely ports. A port is basically a connection point for attaching a single device, such as the NIC of a server to a network, a subnet to a router, etc. They represent entry and exit points for data traffic playing a critical role in OpenStack networking.
Given the importance of ports, it’s clear that any operation on them should perform well, specially at scale and we should be able to catch any regressions ASAP before they land on production environments. Such tests should be done in a periodic fashion and should require doing them on a consistent hardware with enough resources.
In one of our first performance tests using OVN as a backend for OpenStack networking, we found out that port creation would be around 20-30% slower than using ML2/OVS. At this point, those are merely DB operations so there had to be something really odd going on. First thing I did was to measure the time for a single port creation by creating 800 ports in an empty cloud. Each port would belong to a security group with allowed egress traffic and allowed ingress ICMP and SSH. These are the initial results:
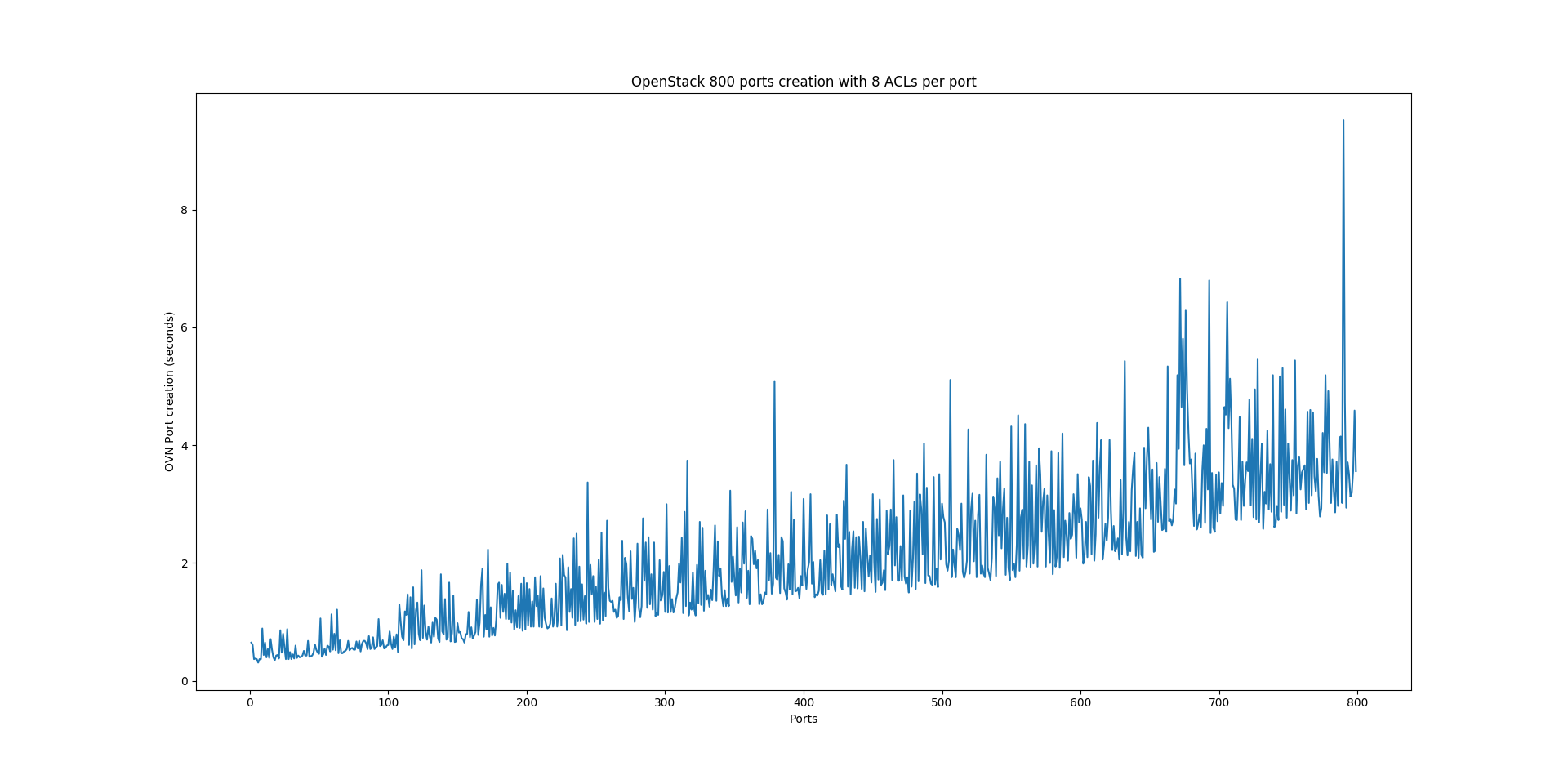
As you can see, the time for creating a single port grows linearly with the number of ports in the cloud. This is obviously a problem at scale that requires further investigation.
In order to understand how a port gets created in OVN, it’s recommended to take a look at the NorthBound database schema and to this interesting blogpost by my colleague Russel Bryant about how Neutron security groups are implemented in OVN. When a port is first created in OVN, the following DB operations will occur:
- Logical_Switch_Port ‘insert’
- Address_Set ‘modify’
- ACL ‘insert’ x8 (one per ACL)
- Logical_Switch_Port ‘modify’ (to add the new 8 ACLs)
- Logical_Switch_Port ‘modify’ (‘up’ = False)
After a closer look to OVN NB database contents, with 800 ports created, there’ll be a total of 6400 ACLs (8 per port) which look all the same except for the inport/outport fields. A first optimization looks obvious: let’s try to get all those 800 ports into the same group and make the ACLs reference that group avoiding duplication. There’s some details and discussions in OpenvSwitch mailing list here. So far so good; we’ll be cutting down the number of ACLs to 8 in this case no matter how big the number of ports in the system increases. This would reduce the number of DB operations considerably and scale better.
However, I went deeper and wanted to understand this linear growth through profiling. I’d like to write a separate blogpost about how to do the profiling but, so far, what I found is that the ‘modify’ operations on the Logical_Switch table to insert the new 8 ACLs would take longer and longer every time (the same goes to the Address_Set table where a new element is added to it with every new port). As the number of elements grow in those two tables, inserting a new element was more expensive. Digging further in the profiling results, it looks like “__apply_diff()” method is the main culprit, and more precisely, “Datum.to_json()”. Here‘s a link to the actual source code.
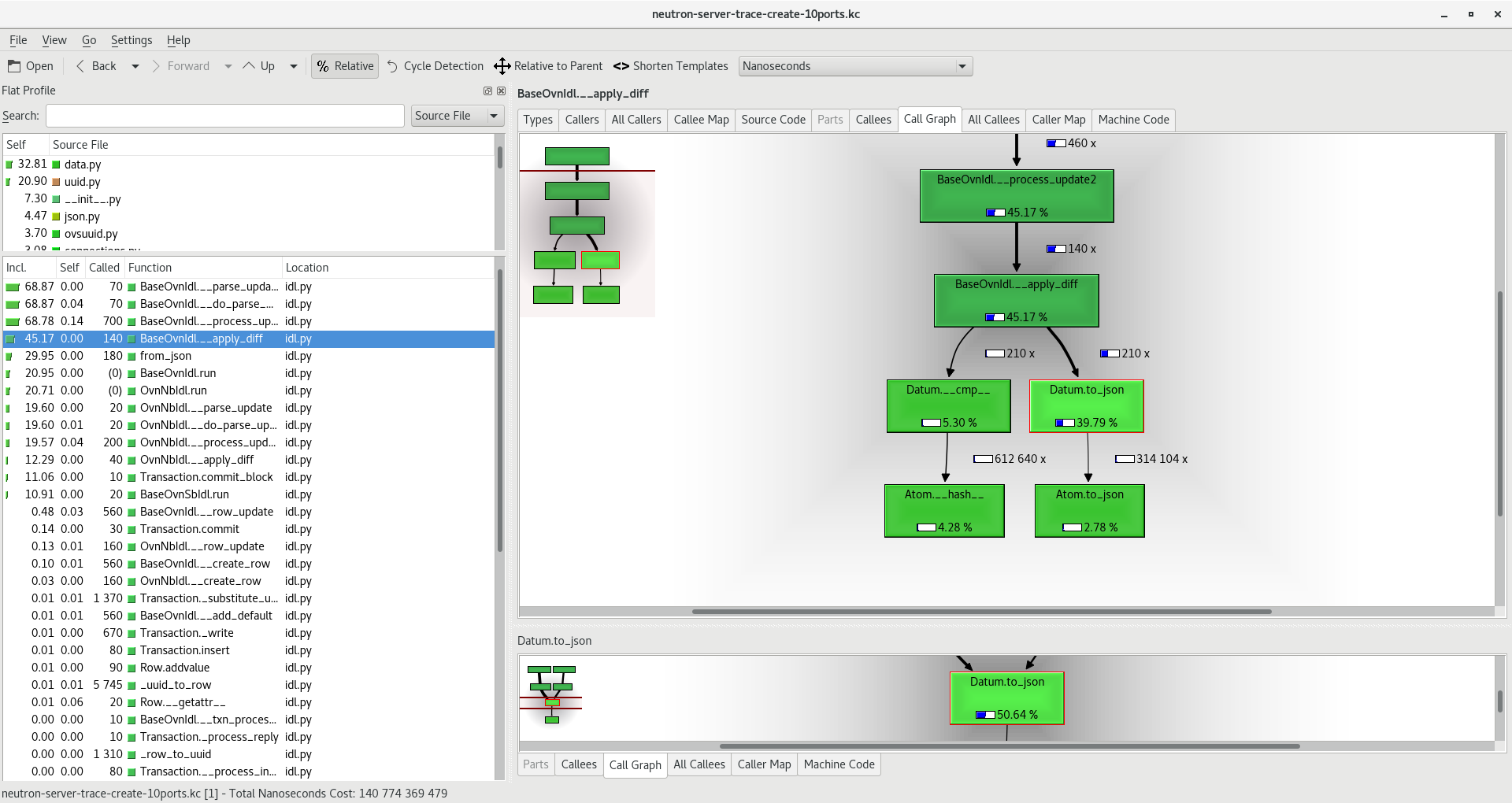
Whenever a ‘modify’ operation happens in OVSDB, ovsdb-server will send a JSON update notification to all clients (it’s actually an update2 notification which is essentially the same but including only the diff with the previous state). This notification is going to be processed by the client (in this case networking-ovn, the OpenStack integration) in the “process_update2” method here and it happens that the Datum.to_json() method is taking most of the execution time. The main questions that came to my mind at this point are:
- How is this JSON data later being used?
- Why do we need to convert to JSON if the original notification was already in JSON?
For 1, it looks like the JSON data is used to build a Row object which will be then used to notify networking-ovn of the change just in case it’d be monitoring any events:
def __apply_diff(self, table, row, row_diff):
old_row_diff_json = {}
for column_name, datum_diff_json in six.iteritems(row_diff):
[...]
old_row_diff_json[column_name] = row._data[column_name].to_json()
[...]
return old_row_diff_json
old_row_diff_json = self.__apply_diff(table, row,
row_update['modify'])
self.notify(ROW_UPDATE, row,
Row.from_json(self, table, uuid, old_row_diff_json))
Doesn’t it look pointless to convert data “to_json” and then back “from_json”? As the number of elements in the row grows, it’ll take longer to produce the associated JSON document (linear growth) of the whole column contents (not just the diff) and the same would go the other way around.
I thought of finding a way to build the Row from the data itself before going through the expensive (and useless) JSON conversions. The patch would look something like this:
diff --git a/python/ovs/db/idl.py b/python/ovs/db/idl.py
index 60548bcf5..5a4d129c0 100644
--- a/python/ovs/db/idl.py
+++ b/python/ovs/db/idl.py
@@ -518,10 +518,8 @@ class Idl(object):
if not row:
raise error.Error('Modify non-existing row')
- old_row_diff_json = self.__apply_diff(table, row,
- row_update['modify'])
- self.notify(ROW_UPDATE, row,
- Row.from_json(self, table, uuid, old_row_diff_json))
+ old_row = self.__apply_diff(table, row, row_update['modify'])
+ self.notify(ROW_UPDATE, row, Row(self, table, uuid, old_row))
changed = True
else:
raise error.Error('<row-update> unknown operation',
@@ -584,7 +582,7 @@ class Idl(object):
row_update[column.name] = self.__column_name(column)
def __apply_diff(self, table, row, row_diff):
- old_row_diff_json = {}
+ old_row = {}
for column_name, datum_diff_json in six.iteritems(row_diff):
column = table.columns.get(column_name)
if not column:
@@ -601,12 +599,12 @@ class Idl(object):
% (column_name, table.name, e))
continue
- old_row_diff_json[column_name] = row._data[column_name].to_json()
+ old_row[column_name] = row._data[column_name].copy()
datum = row._data[column_name].diff(datum_diff)
if datum != row._data[column_name]:
row._data[column_name] = datum
- return old_row_diff_json
+ return old_row
def __row_update(self, table, row, row_json):
changed = False
Now that we have everything in place, it’s time to repeat the tests with the new code and compare the results:

The improvement is obvious! Now the time to create a port is mostly constant regardless of the number of ports in the cloud and the best part is that this gain is not specific to port creation but to ANY modify operation taking place in OVSDB that uses the Python implementation of the OpenvSwitch IDL.
The intent of this blogpost is to show how to deal with performance bottlenecks through profiling and debugging in a top-down fashion, first through simple API calls measuring the time they take to complete and then all the way down to the database changes notifications.
Daniel