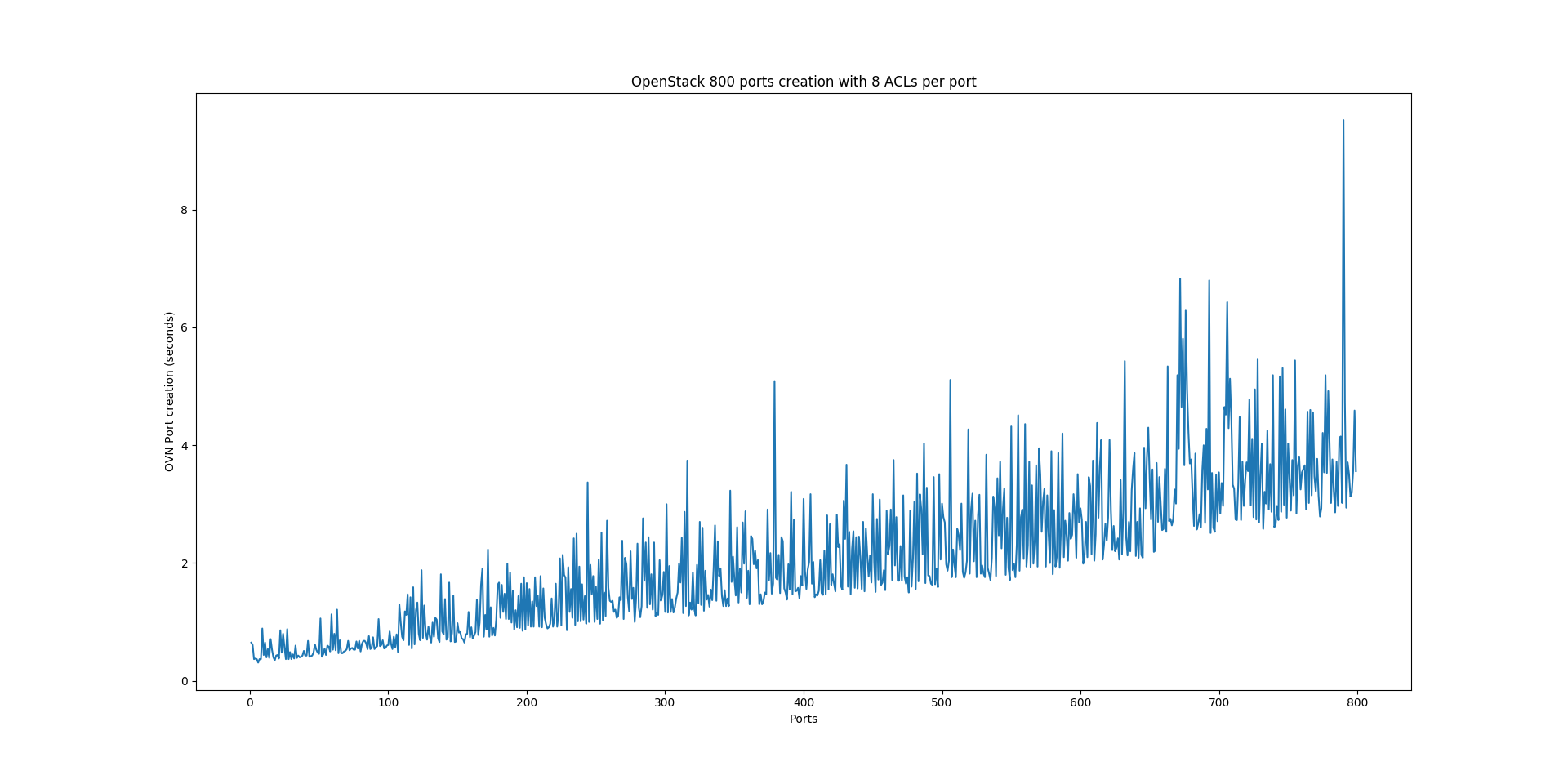
Some time back, when looking at the performance of OpenStack using OVN as the networking backend, we noticed that it didn’t scale really well and it turned out that the major culprit was the way we implemented Neutron Security Groups . In order to illustrate the issue and the optimizations that we carried out, let’s first explain how security was originally implemented:
Networking-ovn and Neutron Security Groups
Originally, Security Groups were implemented using a combination of OVN resources such as Address Sets and Access Control Lists (ACLs):
- Address Sets: An OVN Address set contains a number of IP addresses that can be referenced from an ACL. In networking-ovn we directly map Security Groups to OVN Address Sets: every time a new IP address is allocated for a port, this address will be added to the Address Set(s) representing the Security Groups which the port belongs to.
$ ovn-nbctl list address_set
_uuid : 039032e4-9d98-4368-8894-08e804e9ee78
addresses : ["10.0.0.118", "10.0.0.123", "10.0.0.138", "10.0.0.143"]
external_ids : {"neutron:security_group_id"="0509db24-4755-4321-bb6f-9a094962ec91"}
name : "as_ip4_0509db24_4755_4321_bb6f_9a094962ec91"
- ACLs: They are applied to a Logical Switch (Neutron network). They have a 1-to-many relationship with Neutron Security Group Rules. For instance, when the user creates a single Neutron rule within a Security Group to allow ingress ICMP traffic, it will map to N ACLs in OVN Northbound database with N being the number of ports that belong to that Security Group.
$ openstack security group rule create --protocol icmp default
_uuid : 6f7635ff-99ae-498d-8700-eb634a16903b
action : allow-related
direction : to-lport
external_ids : {"neutron:lport"="95fb15a4-c638-42f2-9035-bee989d80603", "neutron:security_group_rule_id"="70bcb4ca-69d6-499f-bfcf-8f353742d3ff"}
log : false
match : "outport == \"95fb15a4-c638-42f2-9035-bee989d80603\" && ip4 && ip4.src == 0.0.0.0/0 && icmp4"
meter : []
name : []
priority : 1002
severity : []
On the other hand, Neutron has the possibility to filter traffic between ports within the same Security Group or a remote Security Group. One use case may be: a set of VMs whose ports belong to SG1 only allowing HTTP traffic from the outside and another set of VMs whose ports belong to SG2 blocking all incoming traffic. From Neutron, you can create a rule to allow database connections from SG1 to SG2. In this case, in OVN we’ll see ACLs referencing the aforementioned Address Sets. In
$ openstack security group rule create --protocol tcp --dst-port 3306 --remote-group webservers default +-------------------+--------------------------------------+ | Field | Value | +-------------------+--------------------------------------+ | created_at | 2018-12-21T11:29:32Z | | description | | | direction | ingress | | ether_type | IPv4 | | id | 663012c1-67de-45e1-a398-d15bd4f295bb | | location | None | | name | None | | port_range_max | 3306 | | port_range_min | 3306 | | project_id | 471603b575184afc85c67d0c9e460e85 | | protocol | tcp | | remote_group_id | 11059b7d-725c-4740-8db8-5c5b89865d0f | | remote_ip_prefix | None | | revision_number | 0 | | security_group_id | 0509db24-4755-4321-bb6f-9a094962ec91 | | updated_at | 2018-12-21T11:29:32Z | +-------------------+--------------------------------------+
This gets the following OVN ACL into Northbound database:
_uuid : 03dcbc0f-38b2-42da-8f20-25996044e516
action : allow-related
direction : to-lport
external_ids : {"neutron:lport"="7d6247b7-65b9-4864-a9a0-a85bacb4d9ac", "neutron:security_group_rule_id"="663012c1-67de-45e1-a398-d15bd4f295bb"}
log : false
match : "outport == \"7d6247b7-65b9-4864-a9a0-a85bacb4d9ac\" && ip4 && ip4.src == $as_ip4_11059b7d_725c_4740_8db8_5c5b89865d0f && tcp && tcp.dst == 3306"
meter : []
name : []
priority : 1002
severity : []
Problem “at scale”
In order to best illustrate the impact of the optimizations that the Port Groups feature brought in OpenStack, let’s take a look at the number of ACLs on a typical setup when creating just 100 ports on a single network. All those ports will belong to a Security Group with the following rules:
- Allow incoming SSH traffic
- Allow incoming HTTP traffic
- Allow incoming ICMP traffic
- Allow all IPv4 traffic between ports of this same Security Group
- Allow all IPv6 traffic between ports of this same Security Group
- Allow all outgoing IPv4 traffic
- Allow all outgoing IPv6 traffic
Every time we create a port, new 10 ACLs (the 7 rules above + DHCP traffic ACL + default egress drop ACL + default ingress drop ACL) will be created in OVN:
$ ovn-nbctl list ACL| grep ce2ad98f-58cf-4b47-bd7c-38019f844b7b | grep match
match : "outport == \"ce2ad98f-58cf-4b47-bd7c-38019f844b7b\" && ip6 && ip6.src == $as_ip6_0509db24_4755_4321_bb6f_9a094962ec91"
match : "outport == \"ce2ad98f-58cf-4b47-bd7c-38019f844b7b\" && ip"
match : "outport == \"ce2ad98f-58cf-4b47-bd7c-38019f844b7b\" && ip4 && ip4.src == 0.0.0.0/0 && icmp4"
match : "inport == \"ce2ad98f-58cf-4b47-bd7c-38019f844b7b\" && ip4"
match : "outport == \"ce2ad98f-58cf-4b47-bd7c-38019f844b7b\" && ip4 && ip4.src == $as_ip4_0509db24_4755_4321_bb6f_9a094962ec91"
match : "inport == \"ce2ad98f-58cf-4b47-bd7c-38019f844b7b\" && ip6"
match : "outport == \"ce2ad98f-58cf-4b47-bd7c-38019f844b7b\" && ip4 && ip4.src == 0.0.0.0/0 && tcp && tcp.dst == 80"
match : "outport == \"ce2ad98f-58cf-4b47-bd7c-38019f844b7b\" && ip4 && ip4.src == 0.0.0.0/0 && tcp && tcp.dst == 22"
match : "inport == \"ce2ad98f-58cf-4b47-bd7c-38019f844b7b\" && ip4 && ip4.dst == {255.255.255.255, 10.0.0.0/8} && udp && udp.src == 68 && udp.dst == 67"
match : "inport == \"ce2ad98f-58cf-4b47-bd7c-38019f844b7b\" && ip"
With 100 ports, we’ll observe 1K ACLs in the system:
$ ovn-nbctl lsp-list neutron-ebde771e-a93d-438d-a689-d02e9c91c7cf | wc -l 100 $ ovn-nbctl acl-list neutron-ebde771e-a93d-438d-a689-d02e9c91c7cf | wc -l 1000
When ovn-northd sees these new ACLs, it’ll create the corresponding Logical Flows in Southbound database that will then be translated by ovn-controller to OpenFlow flows in the actual hypervisors. The number of Logical Flows also for this 100 ports system can be pulled like this:
$ ovn-sbctl lflow-list neutron-ebde771e-a93d-438d-a689-d02e9c91c7cf | wc -l 3052
At this point, you can pretty much tell that this doesn’t look very promising at scale.
Optimization
One can quickly spot an optimization consisting on having just one ACL per Security Group Rule instead of one ACL per Security Group Rule per port if only we could reference a set of ports and not each port individually on the ‘match’ column of an ACL. This would alleviate calculations mainly on the networking-ovn side where we saw a bottleneck at scale when processing new ports due to the high number of ACLs.
Such optimization would require a few changes on the core OVN side:
- Changes to the schema to create a new table in the Northbound database (Port_Group) and to be able to apply ACLs also to a Port Group.
- Changes to ovn-northd so that it creates new Logical Flows based on ACLs applied to Port Groups.
- Changes to ovn-controller so that it can figure out the physical flows to install on every hypervisor based on the new Logical Flows.
These changes happened mainly in the next 3 patches and the feature is present in OvS 2.10 and beyond:
https://github.com/openvswitch/ovs/commit/3d2848bafa93a2b483a4504c5de801454671dccf
https://github.com/openvswitch/ovs/commit/1beb60afd25a64f1779903b22b37ed3d9956d47c
https://github.com/openvswitch/ovs/commit/689829d53612a573f810271a01561f7b0948c8c8
On the networking-ovn side, we needed to adapt the code as well to:
- Make use of the new feature and implement Security Groups using Port Groups.
- Ensure a migration path from old implementation to Port Groups.
- Keep backwards compatibility: in case an older version of OvS is used, we need to fall back to the previous implementation.
Here you can see the main patch to accomplish the changes above:
https://github.com/openstack/networking-ovn/commit/f01169b405bb5080a1bc1653f79512eb0664c35d
If we attempt to recreate the same scenario as we did earlier where we had 1000 ACLs for 100 ports on our Security Group using the new feature, we can compare the number of resources that we’re now using:
$ ovn-nbctl lsp-list neutron-ebde771e-a93d-438d-a689-d02e9c91c7cf | wc -l 100
Two OVN Port Groups have been created: one for our Security Group and then neutron-pg-drop which is used to add fallback, low priority drop ACLs (by default OVN will allow all traffic if no explicit drop ACLs are added):
$ ovn-nbctl --bare --columns=name list Port_Group neutron_pg_drop pg_0509db24_4755_4321_bb6f_9a094962ec91
ACLs are now applied to Port Groups and not to the Logical Switch:
$ ovn-nbctl acl-list neutron-ebde771e-a93d-438d-a689-d02e9c91c7cf | wc -l 0 $ ovn-nbctl acl-list pg_0509db24_4755_4321_bb6f_9a094962ec91 | wc -l 7 $ ovn-nbctl acl-list neutron_pg_drop | wc -l 2
The number of ACLs has gone from 1000 (10 per port) to just 9 regardless of the number of ports in the system:
$ ovn-nbctl --bare --columns=match list ACL inport == @pg_0509db24_4755_4321_bb6f_9a094962ec91 && ip4 inport == @pg_0509db24_4755_4321_bb6f_9a094962ec91 && ip6 inport == @neutron_pg_drop && ip outport == @pg_0509db24_4755_4321_bb6f_9a094962ec91 && ip4 && ip4.src == 0.0.0.0/0 && tcp && tcp.dst == 22 outport == @pg_0509db24_4755_4321_bb6f_9a094962ec91 && ip4 && ip4.src == 0.0.0.0/0 && icmp4 outport == @pg_0509db24_4755_4321_bb6f_9a094962ec91 && ip6 && ip6.src == $pg_0509db24_4755_4321_bb6f_9a094962ec91_ip6 outport == @pg_0509db24_4755_4321_bb6f_9a094962ec91 && ip4 && ip4.src == $pg_0509db24_4755_4321_bb6f_9a094962ec91_ip4 outport == @pg_0509db24_4755_4321_bb6f_9a094962ec91 && ip4 && ip4.src == 0.0.0.0/0 && tcp && tcp.dst == 80 outport == @neutron_pg_drop && ip
This change was merged in OpenStack Queens and requires OvS 2.10 at least. Also, if upgrading from an earlier version of either OpenStack or OvS, networking-ovn will take care of the migration from Address Sets to Port Groups upon start of Neutron server and the new implementation will be automatically used.
As a bonus, this enables the possibility of applying the conjunctive match action easier on Logical Flows resulting in a big performance improvement as it was reported here.