Nowadays, with the huge amount of virtualization in the workloads, it is becoming more and more popular to see pure layer-3 Spine and Leaf datacenters. This overcomes the challenge of having large L2 domains (complex at scale, significant failure domains, …), and since most of the switching devices these days are capable of doing routing, it makes more sense to move to a pure Layer 3 fabric design where L2 connectivity is only assumed within a rack or leaf.
The goal of this blogpost is to experiment with the idea of having a single OVN Logical Switch (L2 domain in the overlay) on a pure L3 underlay without using tunnels as well as to set the grounds for further ideas and code to support this type of deployments.
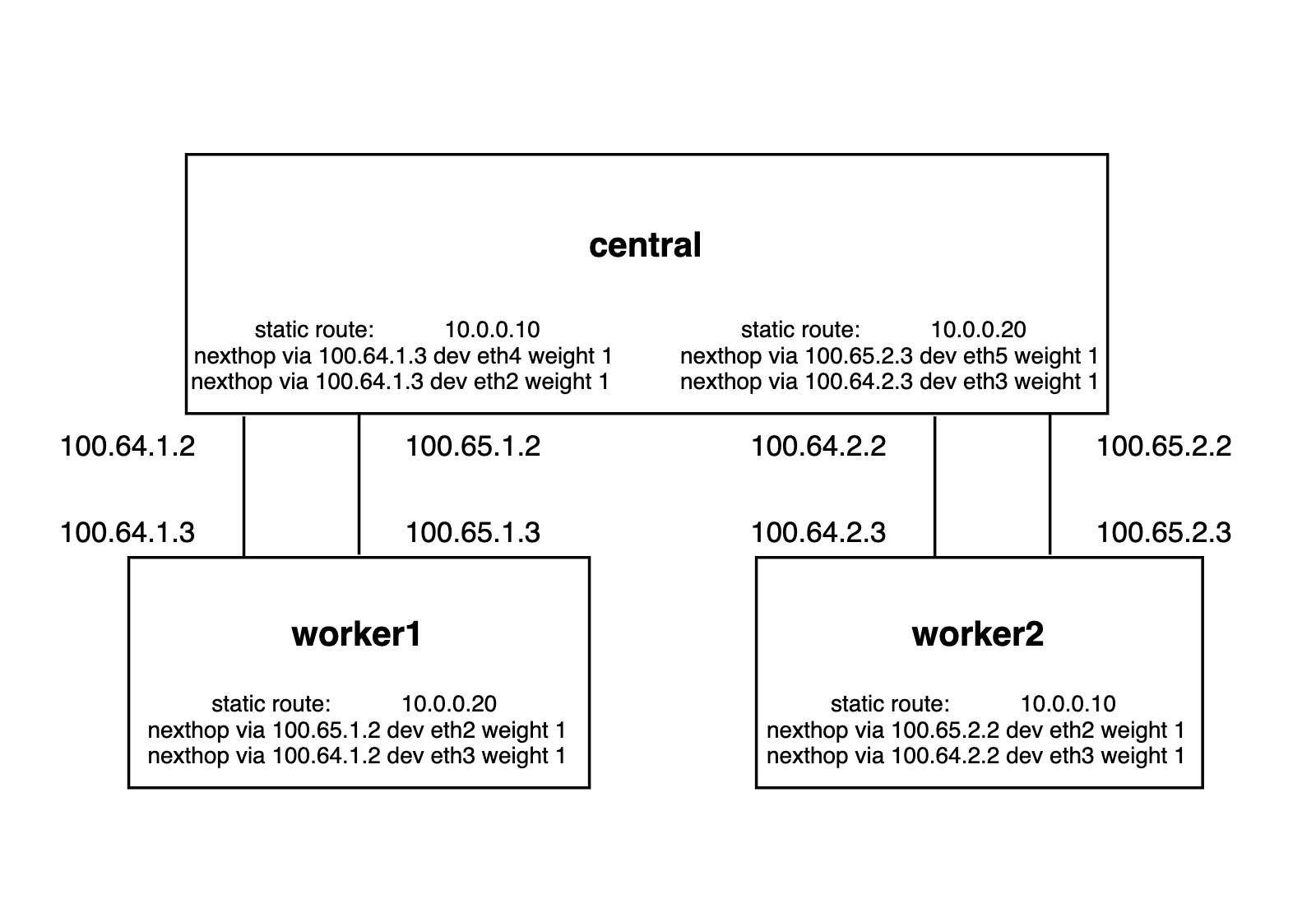
As a playground, I have set up the following 3 machines topology:
From an OVN perspective, the topology is pretty simple as well: one Logical Switch and two VMs (actually, network namespaces with an OVS port), placed on separate workers:
[root@central ~]# ovn-nbctl show
switch 03145198-0722-452a-b381-032dcec47cd9 (public)
port public-segment1
type: localnet
addresses: ["unknown"]
port vm1
addresses: ["40:44:00:00:00:01 10.0.0.10"]
port vm2
addresses: ["40:44:00:00:00:02 10.0.0.20"]
[root@central ~]# ovn-sbctl show
Chassis worker1
hostname: worker1
Encap geneve
ip: "192.168.50.100"
options: {csum="true"}
Port_Binding vm1
Chassis worker2
hostname: worker2
Encap geneve
ip: "192.168.50.101"
options: {csum="true"}
Port_Binding vm2As we are only interested (for now) in the data plane implications, I have set up a dedicated shared network across the 3 machines for the OVN control plane. So for now, L2 is only assumed for OVN control plane.
Traffic flow between vm1 and vm2
ARP Resolution
When vm1 (10.0.0.10) wants to communicate with vm2 (10.0.0.20) it first needs to resolve its MAC address. Normally, ovn-controller will reply to vm1’s ARP request with the MAC address of vm2. On a typical deployment where L2 connectivity is present, this would just work as the traffic would be placed on the wire and picked by ovn-controller where the destination machine is running.
However, this is no longer true so we need to figure out a way to place the traffic into vm1’s kernel to do the routing through our 100.{64, 65}.{1, 2}.0/24 networks. The answer to this is the Proxy ARP technique.
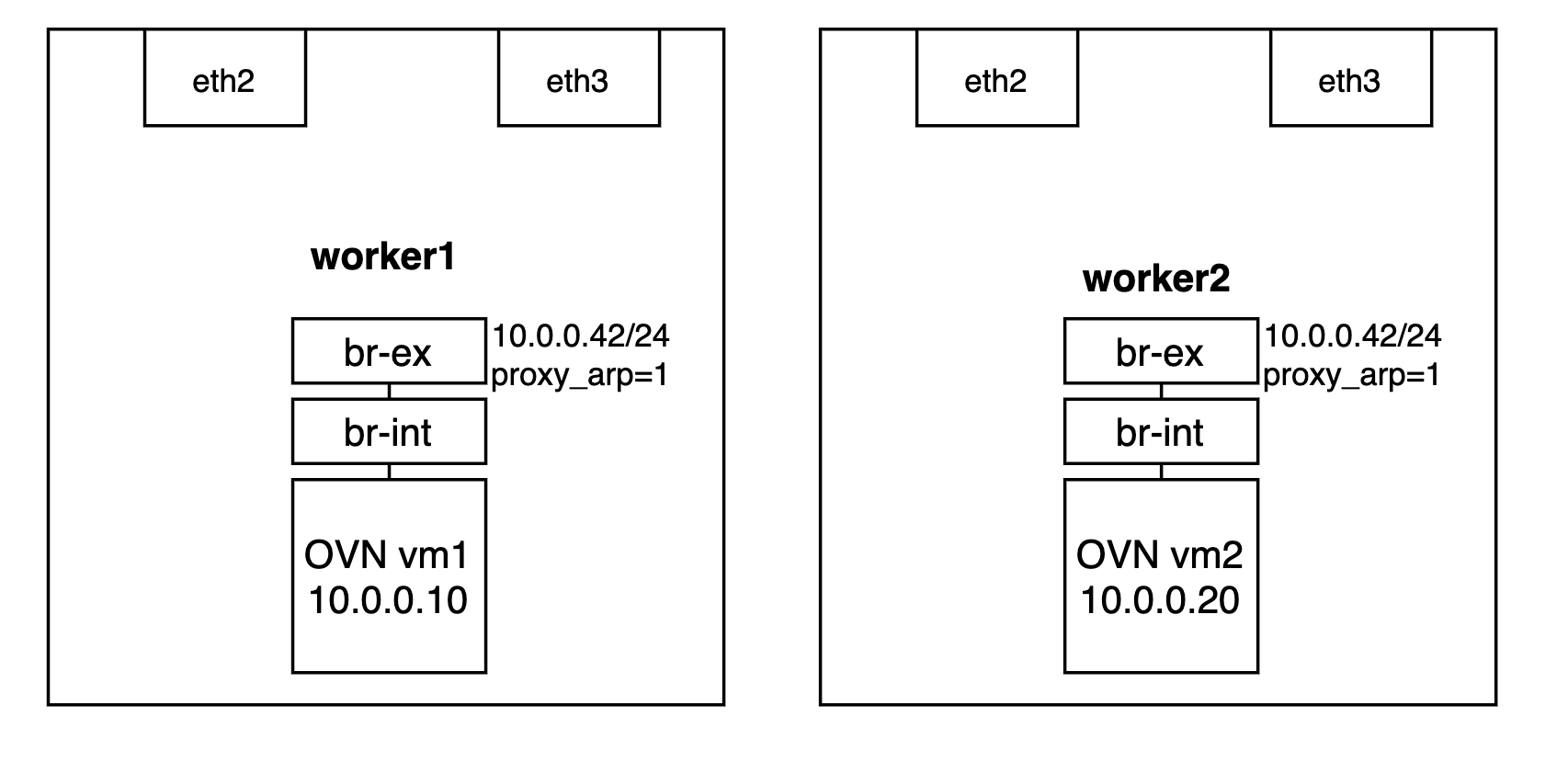
On a traditional OVN setup, we would have the NIC attached to br-ex and the traffic will hit it via a patch-port between br-int and br-ex. Now, we won’t have any NIC attached to br-ex. Instead, we’ll have an IP within the same virtual segment and we’ll enable proxy_arp on the br-ex interface:
# Enable proxy-ARP and forwarding
ip link set dev br-ex up
ip address add 10.0.0.42/24 dev br-ex
sudo sysctl -w net.ipv4.conf.br-ex.proxy_arp=1
sudo sysctl -w net.ipv4.ip_forward=1At this point, we need to prevent OVN from responding to ARP requests that are directed to VMs outside the worker node. For now, let’s just remove the ARP responder flows manually (hack!):
uuid=0xb9394db0, table=14(ls_in_arp_rsp), priority=50 , match=(arp.tpa == 10.0.0.20 && arp.op == 1), action=(eth.dst = eth.src; eth.src = 40:44:00:00:00:02; arp.op = 2; /* ARP reply */ arp.tha = arp.sha; arp.sha = 40:44:00:00:00:02; arp.tpa = arp.spa; arp.spa = 10.0.0.20; outport = inport; flags.loopback = 1; output;)
uuid=0x7c4824a5,table=14(ls_in_arp_rsp), priority=50 , match=(arp.tpa == 10.0.0.10 && arp.op == 1), action=(eth.dst = eth.src; eth.src = 40:44:00:00:00:01; arp.op = 2; /* ARP reply */ arp.tha = arp.sha; arp.sha = 40:44:00:00:00:01; arp.tpa = arp.spa; arp.spa = 10.0.0.10; outport = inport; flags.loopback = 1; output;Now, on worker1 (vm1) we’ll remove the corresponding OpenFlow for the ARP responder of vm2 and vice-versa:
[vagrant@worker1 ~]$ sudo ovs-ofctl del-flows br-int cookie=0xb9394db0/-1
[vagrant@worker2 ~]$ sudo ovs-ofctl del-flows br-int cookie=0x7c4824a5/-1
With this setup, we expect br-ex to reply for the ARP requests and each VM will learn the MAC address of br-ex instead of the actual one for the remote VM:
[vagrant@worker1 ~]$ sudo ip address show br-ex
8: br-ex: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 9a:a1:47:9b:36:45 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.42/24 scope global br-ex
valid_lft forever preferred_lft forever
inet6 fe80::98a1:47ff:fe9b:3645/64 scope link
valid_lft forever preferred_lft forever
[vagrant@worker1 ~]$ sudo ip netns exec vm1 ip nei | grep 10.0.0.20
10.0.0.20 dev vm1 lladdr 9a:a1:47:9b:36:45 REACHABLE
[root@worker2 ~]# sudo ip address show br-ex
9: br-ex: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 72:84:42:d8:f6:48 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.42/24 scope global br-ex
valid_lft forever preferred_lft forever
inet6 fe80::7084:42ff:fed8:f648/64 scope link
valid_lft forever preferred_lft forever
[root@worker2 ~]# sudo ip netns exec vm2 ip nei | grep 10.0.0.10
10.0.0.10 dev vm2 lladdr 72:84:42:d8:f6:48 REACHABLE
Now that we have solved the L2 portion, we need to steer the traffic through the L3 networks with the central node (our leaf / ToR switch).
Routing
Ideally, we would have BGP speakers running on each node advertising host routes to our VMs. This way we could learn the routes dynamically without any configuration needed on the ToRs or on the hypervisors.
As a first step, I have omitted this for now and configured routes statically:
[root@central ~]# ip route
default via 192.168.121.1 dev eth0 proto dhcp metric 100
10.0.0.10
nexthop via 100.64.1.3 dev eth4 weight 1
nexthop via 100.65.1.3 dev eth2 weight 1
10.0.0.20
nexthop via 100.64.2.3 dev eth5 weight 1
nexthop via 100.65.2.3 dev eth3 weight 1
100.64.1.0/24 dev eth4 proto kernel scope link src 100.64.1.2 metric 104
100.64.2.0/24 dev eth5 proto kernel scope link src 100.64.2.2 metric 105
100.65.1.0/24 dev eth2 proto kernel scope link src 100.65.1.2 metric 102
100.65.2.0/24 dev eth3 proto kernel scope link src 100.65.2.2 metric 103
192.168.50.0/24 dev eth1 proto kernel scope link src 192.168.50.10 metric 101
192.168.121.0/24 dev eth0 proto kernel scope link src 192.168.121.52 metric 100
[vagrant@worker1 ~]$ ip route
default via 192.168.121.1 dev eth0 proto dhcp metric 100
10.0.0.0/24 dev br-ex proto kernel scope link src 10.0.0.42
10.0.0.20
nexthop via 100.65.1.2 dev eth2 weight 1
nexthop via 100.64.1.2 dev eth3 weight 1
100.64.1.0/24 dev eth3 proto kernel scope link src 100.64.1.3 metric 103
100.65.1.0/24 dev eth2 proto kernel scope link src 100.65.1.3 metric 102
192.168.50.0/24 dev eth1 proto kernel scope link src 192.168.50.100 metric 101
192.168.121.0/24 dev eth0 proto kernel scope link src 192.168.121.27 metric 100
[root@worker2 ~]# ip route
default via 192.168.121.1 dev eth0 proto dhcp metric 100
10.0.0.0/24 dev br-ex proto kernel scope link src 10.0.0.42
10.0.0.10
nexthop via 100.65.2.2 dev eth2 weight 1
nexthop via 100.64.2.2 dev eth3 weight 1
100.64.2.0/24 dev eth3 proto kernel scope link src 100.64.2.3 metric 103
100.65.2.0/24 dev eth2 proto kernel scope link src 100.65.2.3 metric 102
192.168.50.0/24 dev eth1 proto kernel scope link src 192.168.50.101 metric 101
192.168.121.0/24 dev eth0 proto kernel scope link src 192.168.121.147 metric 100You can notice that there are Equal-cost multi-path (ECMP) routes to the 100.{64, 65}.x.x networks. This provides load balancing using a 5-tuple hash algorithm as two NICs are going to be used for our data plane traffic.
Combined with the use of Bidirectional Forwarding Detection (BFD) we could as well provide fault tolerance by detecting when one of the links go down and steer all the traffic through the other link. For the sake of this blogpost, we’ll ignore this part.
With the routes listed above and ARP proxy enabled on both worker nodes, we’re now able to route the traffic between the two VMs:
[vagrant@worker1 ~]$ sudo ip netns exec vm1 ping 10.0.0.20 -c4
PING 10.0.0.20 (10.0.0.20) 56(84) bytes of data.
64 bytes from 10.0.0.20: icmp_seq=1 ttl=61 time=0.891 ms
64 bytes from 10.0.0.20: icmp_seq=2 ttl=61 time=0.563 ms
64 bytes from 10.0.0.20: icmp_seq=3 ttl=61 time=0.701 ms
64 bytes from 10.0.0.20: icmp_seq=4 ttl=61 time=0.772 ms
--- 10.0.0.20 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 0.563/0.731/0.891/0.123 msAlso we can check that the ECMP routes are working by inspecting the ICMP traffic on eth2/eth3 on one of the workers while the ping is running:
[root@worker2 ~]# tcpdump -i eth2 -vvne icmp
tcpdump: listening on eth2, link-type EN10MB (Ethernet), capture size 262144 bytes
11:55:18.523039 52:54:00:c2:46:52 > 52:54:00:3c:9e:fd, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 62387, offset 0, flags [none], proto ICMP (1), length 84)
10.0.0.20 > 10.0.0.10: ICMP echo reply, id 9935, seq 7, length 64
11:55:19.523825 52:54:00:c2:46:52 > 52:54:00:3c:9e:fd, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 62817, offset 0, flags [none], proto ICMP (1), length 84)
10.0.0.20 > 10.0.0.10: ICMP echo reply, id 9935, seq 8, length 64
[root@worker2 ~]# tcpdump -i eth3 -vvnee icmp
tcpdump: listening on eth3, link-type EN10MB (Ethernet), capture size 262144 bytes
11:55:24.524921 52:54:00:86:a6:67 > 52:54:00:76:11:56, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 62, id 9656, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.0.10 > 10.0.0.20: ICMP echo request, id 9935, seq 13, length 64
11:55:25.526151 52:54:00:86:a6:67 > 52:54:00:76:11:56, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 62, id 10378, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.0.10 > 10.0.0.20: ICMP echo request, id 9935, seq 14, length 6411:55:26.527168 52:54:00:86:a6:67 > 52:54:00:76:11:56, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 62, id 11334, offset 0, flags [DF], proto ICMP (1), length 84)
We can see that the ICMP requests are arriving on one interface (eth2) while the ICMP replies are being sent on the other (eth3) effectively splitting the load across the two NICs.
Next steps:
- Add support in OVN for Proxy ARP (right now, we are using Proxy ARP in the kernel and removing the ARP responder flows manually)
- Adding BGP support to this deployment in order to avoid the static configuration of the nodes and routers
- Add BFD capabilities to provide fault tolerance
I have written an automated setup based on Vagrant that will deploy and configure everything as explained above. You can clone it from here.