Almost a year ago I reported a bug we were hitting in OpenStack using networking-ovn as a network backend. The symptom was that sometimes Tempest tests were failing in the gate when trying to reach a Floating IP of a VM. The failure rate was not really high so a couple of ‘rechecks’ here and there was enough for us to delay chasing down the bug.
Last week I decided to hunt the bug and attempt to find out the root cause of the failure. Why was the FIP unreachable? For a FIP to be reachable from the external network (Tempest), the following high-level steps should happen:
- Tempest needs to ARP query the FIP of the VM
- A TCP SYN packet is sent out to the FIP
- Routing will happen between external network and internal VM network
- The packet will reach the VM and it’ll respond back with a SYN/ACK packet to the originating IP (Tempest executor)
- Routing will happen between internal VM network and external network
- SYN/ACK packet reaches Tempest executor and the connection will get established on its side
- ACK sent to the VM
- …
Some of those steps are clearly failing so time to figure out which.
2018-09-18 17:09:17,276 13788 ERROR [tempest.lib.common.ssh] Failed to establish authenticated ssh connection to cirros@172.24.5.11 after 15 attempts
As first things come first, let’s start off by checking that we get the ARP response of the FIP. We spawn a tcpdump on the external interface where Tempest runs and check traffic to/from 172.24.5.11:
Sep 18 17:09:17.644405 ubuntu-xenial-ovh-bhs1-0002095917 tcpdump[28445]: 17:09:17.275597 1e:d5:ec:49:df:4f > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 172.24.5.11 tell 172.24.5.1, length 28
I can see plenty of those ARP requests but not a single reply. Something’s fishy…
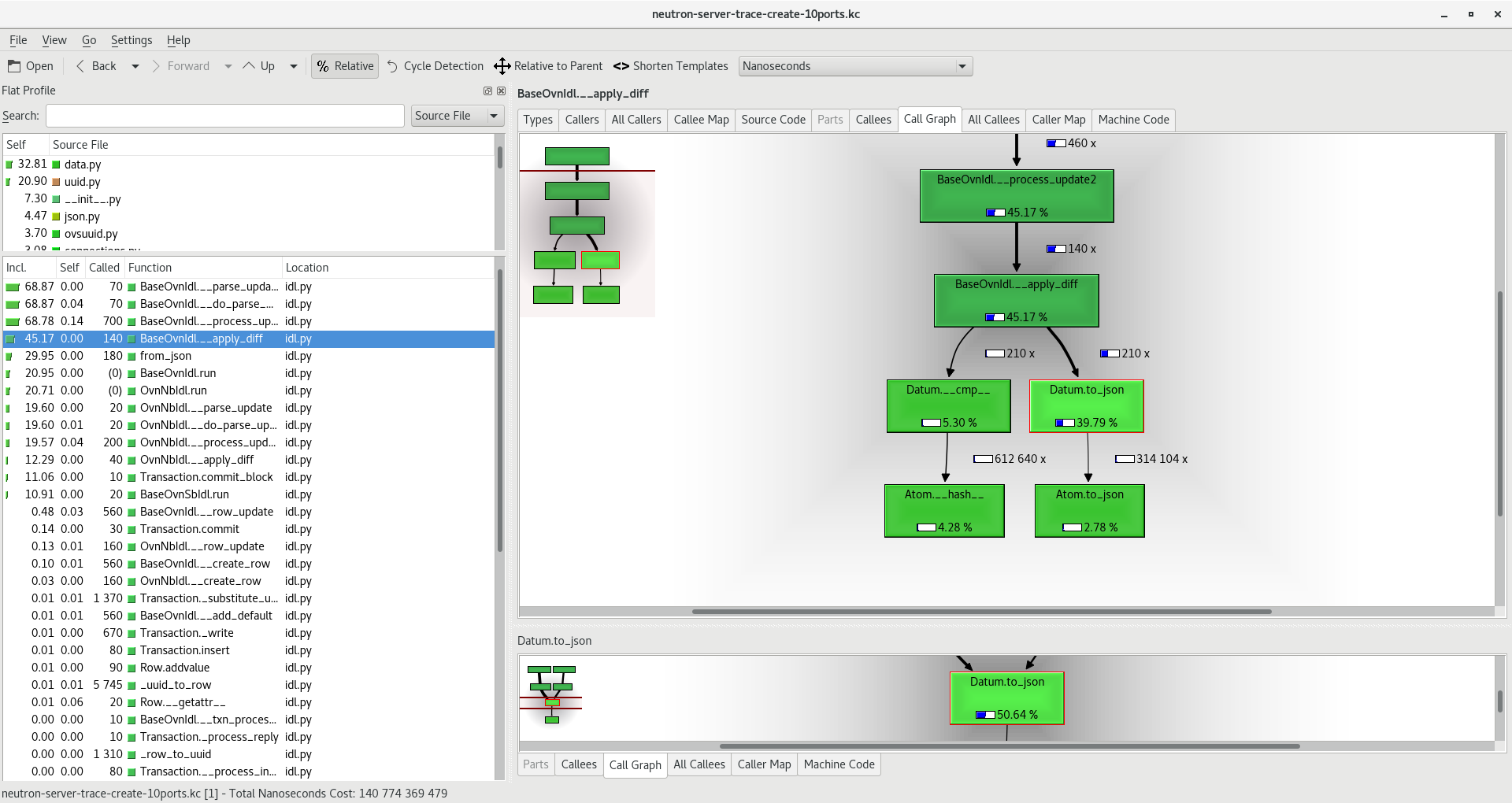
In OVN, ARP queries are responded by ovn-controller so they should hit the gateway node. Let’s inspect the flows there to see if they were installed in OVN Ingress table 1 (which corresponds to OpenFlow table 9):
http://www.openvswitch.org/support/dist-docs/ovn-northd.8.html
Ingress Table 1: IP Input
These flows reply to ARP requests for the virtual IP
addresses configured in the router for DNAT or load bal‐
ancing. For a configured DNAT IP address or a load bal‐
ancer VIP A, for each router port P with Ethernet address
E, a priority-90 flow matches inport == P && arp.op == 1
&& arp.tpa == A (ARP request) with the following actions:
eth.dst = eth.src;
eth.src = E;
arp.op = 2; /* ARP reply. */
arp.tha = arp.sha;
arp.sha = E;
arp.tpa = arp.spa;
arp.spa = A;
outport = P;
flags.loopback = 1;
output;
$ sudo ovs-ofctl dump-flows br-int | grep table=9 | grep "arp_tpa=172.24.5.11"
cookie=0x549ad196, duration=105.055s, table=9, n_packets=0, n_bytes=0, idle_age=105, priority=90,arp,reg14=0x1,metadata=0x87,arp_tpa=172.24.5.11,arp_op=1 actions=move:NXM_OF_ETH_SRC[]->NXM_OF_ETH_DST[],load:0x2->NXM_OF_ARP_OP[],move:NXM_NX_ARP_SHA[]->NXM_NX_ARP_THA[],mod_dl_src:fa:16:3e:3d:bf:46,load:0xfa163e3dbf46->NXM_NX_ARP_SHA[],move:NXM_OF_ARP_SPA[]->NXM_OF_ARP_TPA[],load:0xac18050b->NXM_OF_ARP_SPA[],load:0x1->NXM_NX_REG15[],load:0x1->NXM_NX_REG10[0],resubmit(,32)
So the flow for the ARP responder is installed but it has no hits (note n_packets=0). Looks like for some reason the ARP query is not reaching the router pipeline from the public network. Let’s now take a look at the Logical Router:
This is how the Logical Router looks like:
$ ovn-nbctl show
router 71c37cbd-4aa9-445d-a9d1-cb54ee1d3207 (neutron-cc163b42-1fdf-4cfa-a2ff-50c521f04222) (aka tempest-TestSecurityGroupsBasicOps-router-1912572360)
port lrp-2a1bbf89-adee-4e74-b65e-1ac7a1ba4089
mac: "fa:16:3e:3d:bf:46"
networks: ["10.1.0.1/28"]
nat 2eaaa99e-3be8-49ad-b801-ad198a6084fd
external ip: "172.24.5.7"
logical ip: "10.1.0.0/28"
type: "snat"
nat 582bab87-8acb-4905-8723-948651811193
external ip: "172.24.5.11"
logical ip: "10.1.0.6"
type: "dnat_and_snat"
We can see that we have two NAT entries: one for the FIP (172.24.5.11 <-> 10.1.0.6) and one SNAT entry for the gateway which should allow the VM to access the external network.
There’s also one router port which connects the VM subnet to the router but… wait …There’s no gateway port connected to the router!! This means that the FIP is unreachable so at this point we know what’s going on but… WHY? We need to figure out why the gateway port is not added. Time to check the code and logs:
Code wise (see below), the gateway is added upon router creation. It’ll imply creating a router (L9), the gateway port (L26) and adding it to the Logical Switch as you can see here. Afterwards, it’ll add a static route with the next hop to the router (L37). Also, you can see that everything is inside a context manager (L8) where a transaction with OVSDB is created so all the commands are expected to be commited/failed as a whole:
def create_router(self, router, add_external_gateway=True):
"""Create a logical router."""
context = n_context.get_admin_context()
external_ids = self._gen_router_ext_ids(router)
enabled = router.get('admin_state_up')
lrouter_name = utils.ovn_name(router['id'])
added_gw_port = None
with self._nb_idl.transaction(check_error=True) as txn:
txn.add(self._nb_idl.create_lrouter(lrouter_name,
external_ids=external_ids,
enabled=enabled,
options={}))
if add_external_gateway:
networks = self._get_v4_network_of_all_router_ports(
context, router['id'])
if router.get(l3.EXTERNAL_GW_INFO) and networks is not None:
added_gw_port = self._add_router_ext_gw(context, router,
networks, txn)
def _add_router_ext_gw(self, context, router, networks, txn):
router_id = router['id']
# 1. Add the external gateway router port.
gw_info = self._get_gw_info(context, router)
gw_port_id = router['gw_port_id']
port = self._plugin.get_port(context, gw_port_id)
self._create_lrouter_port(router_id, port, txn=txn)
columns = {}
if self._nb_idl.is_col_present('Logical_Router_Static_Route',
'external_ids'):
columns['external_ids'] = {
ovn_const.OVN_ROUTER_IS_EXT_GW: 'true',
ovn_const.OVN_SUBNET_EXT_ID_KEY: gw_info.subnet_id}
# 2. Add default route with nexthop as gateway ip
lrouter_name = utils.ovn_name(router_id)
txn.add(self._nb_idl.add_static_route(
lrouter_name, ip_prefix='0.0.0.0/0', nexthop=gw_info.gateway_ip,
**columns))
# 3. Add snat rules for tenant networks in lrouter if snat is enabled
if utils.is_snat_enabled(router) and networks:
self.update_nat_rules(router, networks, enable_snat=True, txn=txn)
return port
So, how is it possible that the Logical Router exists while the gateway port does not if everything is under the same transaction? We’re nailing this down and now we need to figure that out by inspecting the transactions in neutron-server logs:
DEBUG ovsdbapp.backend.ovs_idl.transaction [-] Running txn n=1 command(idx=2): AddLRouterCommand(may_exist=True, columns={'external_ids': {'neutron:gw_port_id': u'8dc49792-b37a-48be-926a-af2c76e269a9', 'neutron:router_name': u'tempest-TestSecurityGroupsBasicOps-router-1912572360', 'neutron:revision_number': '2'}, 'enabled': True, 'options': {}}, name=neutron-cc163b42-1fdf-4cfa-a2ff-50c521f04222) {{(pid=32314) do_commit /usr/local/lib/python2.7/dist-packages/ovsdbapp/backend/ovs_idl/transaction.py:84}}
The above trace is written when the Logical Router gets created but surprisingly we can see idx=2 meaning that it’s not the first command of a transaction. But… How is this possible? We saw in the code that it was the first command to be executed when creating a router and this is the expected sequence:
- AddLRouterCommand
- AddLRouterPortCommand
- SetLRouterPortInLSwitchPortCommand
- AddStaticRouteCommand
Let’s check the other commands in this transaction in the log file:
DEBUG ovsdbapp.backend.ovs_idl.transaction [-] Running txn n=1 command(idx=0): AddLRouterPortCommand(name=lrp-1763c78f-5d0d-41d4-acc7-dda1882b79bd, may_exist=True, lrouter=neutron-d1d3b2f2-42cb-4a86-ac5a-77001da8fee2, columns={'mac': u'fa:16:3e:e7:63:b9', 'external_ids': {'neutron:subnet_ids': u'97d41327-4ea6-4fff-859c-9884f6d1632d', 'neutron:revision_number': '3', 'neutron:router_name': u'd1d3b2f2-42cb-4a86-ac5a-77001da8fee2'}, 'networks': [u'10.1.0.1/28']}) {{(pid=32314) do_commit /usr/local/lib/python2.7/dist-packages/ovsdbapp/backend/ovs_idl/transaction.py:84}}
DEBUG ovsdbapp.backend.ovs_idl.transaction [-] Running txn n=1 command(idx=1): SetLRouterPortInLSwitchPortCommand(if_exists=True, lswitch_port=1763c78f-5d0d-41d4-acc7-dda1882b79bd, lrouter_port=lrp-1763c78f-5d0d-41d4-acc7-dda1882b79bd, is_gw_port=False, lsp_address=router) {{(pid=32314) do_commit /usr/local/lib/python2.7/dist-packages/ovsdbapp/backend/ovs_idl/transaction.py:84}}
DEBUG ovsdbapp.backend.ovs_idl.transaction [-] Running txn n=1 command(idx=2): AddLRouterCommand(may_exist=True, columns={'external_ids': {'neutron:gw_port_id': u'8dc49792-b37a-48be-926a-af2c76e269a9', 'neutron:router_name': u'tempest-TestSecurityGroupsBasicOps-router-1912572360', 'neutron:revision_number': '2'}, 'enabled': True, 'options': {}}, name=neutron-cc163b42-1fdf-4cfa-a2ff-50c521f04222)
DEBUG ovsdbapp.backend.ovs_idl.transaction [-] Running txn n=1 command(idx=3): AddNATRuleInLRouterCommand(lrouter=neutron-d1d3b2f2-42cb-4a86-ac5a-77001da8fee2, columns={'external_ip': u'172.24.5.26', 'type': 'snat', 'logical_ip': '10.1.0.0/28'}) {{(pid=32314) do_commit /usr/local/lib/python2.7/dist-packages/ovsdbapp/backend/ovs_idl/transaction.py:84}}
It looks like this:
- AddLRouterPortCommand
- SetLRouterPortInLSwitchPortCommand
- AddLRouterCommand (our faulty router)
- AddNATRuleInLRouterCommand
Definitely, number 3 is our command that got in between a totally different transaction from a totally different test being executed concurrently in the gate . Most likely, according to the commands 1, 2 and 4 it’s another test adding a new interface to a different router here. It’ll create a logical router port, add it to the switch and update the SNAT rules. All those debug traces come from the same process ID so the transactions are getting messed up from the two concurrent threads attempting to write into OVSDB.
This is the code that will create a new transaction object in ovsdbapp or, if it was already created, will return the same object. The problem here comes when two different threads/greenthreads attempt to create their own separate transactions concurrently:
@contextlib.contextmanager
def transaction(self, check_error=False, log_errors=True, **kwargs):
"""Create a transaction context.
:param check_error: Allow the transaction to raise an exception?
:type check_error: bool
:param log_errors: Log an error if the transaction fails?
:type log_errors: bool
:returns: Either a new transaction or an existing one.
:rtype: :class:`Transaction`
"""
if self._nested_txn:
yield self._nested_txn
else:
with self.create_transaction(
check_error, log_errors, **kwargs) as txn:
self._nested_txn = txn
try:
yield txn
finally:
self._nested_txn = None
- Test1 will open a new transaction and append AddLRouterPortCommand and SetLRouterPortInLSwitchPortCommand commands to it.
- Test1 will now yield its execution (due to some I/O in the case of greenthreads as eventlet is heavily used in OpenStack).
- Test 2 (our failing test!) will attempt to create its own transaction.
- As everything happens in the same process, self._nested_txn was previously assigned due to step number 1 and is returned here.
- Test 2 will append the AddLRouterCommand command to it.
- At this point Test 2 will also yield its execution. Mainly due to the many debug traces that we have for scheduling a gateway port on the available chassis in OVN so this is one of the most likely parts of the code for the race condition to occur.
- Test 1 will append the rest of the commands and commit the transaction to OVSDB.
- OVSDB will execute the commands and close the transaction.
- When Test 2 appends the rest of its commands, the transaction is closed and will never get commited, ie. only AddLRouterCommand was applied to the DB leaving the gateway port behind in OVN.
The nested transaction mechanism in ovsdbapp was not taking into account that two different threads attempt to open separate transactions so we needed to patch this to make it thread safe. The solution that we came up with was to create a different transaction per thread ID and add the necessary coverage to the unit tests.
Two more questions arise at this point:
- Why this is not happening in Neutron if they also use ovsdbapp there?
Perhaps it’s happening but they don’t make that much use of multiple commands transactions. Instead, most of the time it’s single command transactions that are less prone to this particular race condition.
- Why does it happen mostly when creating a gateway port?
Failing to create a gateway port leads to VMs to lose external connectivity so the failure is very obvious. There might be other conditions where this bug happens and we’re not even realizing, producing weird behaviors. However, it’s true that this particular code which creates the gateway port is complex as it implies scheduling the port into the least loaded available chassis so a number of DEBUG traces were added. As commented through the blog post, writing these traces will result in yielding the execution to a different greenthread where the disaster occurs!
This blog post tries to show a top-bottom approach to debugging failures that are not easily reproducible. It requires a solid understanding of the system architecture (OpenStack components, OVN, databases) and its underlying technologies (Python, greenthreads) to be able to tackle this kind of race conditions in an effective way.